


Methodology - toward neural networks

Applying neural networks for practical purposes requires more than just good knowledge of what are the existing algorithms and their working principles.
A machine learning practitioner needs to know how to choose an algorithm architecture for a particular application and how to monitor it and respond to feedback for its improvement. These include:
determining the goal - goals and performance metrics must be driven by the
problem that the application is intended to solve
decision on whether to gather more data - diagnose if poor performance is due to overfitting, or if adding or removing regularizing features is required
increase or decrease model capacity - configuring number of nodes and layers in the neura network, adjusting hyperparameters further
debug software implementation of the algorithm - diagnose if there’s defect in the data or software (framework used)
📌 The Goal
An important consideration besides the target value or benchmark of the performance metric is the choice of which metric to use. Several performance metrics may be used to measure the effectiveness of the application and they are usually different from the loss functions used while training the neural network.
“Metrics are how humans draw meaning from data and are typically designed for end users of the application. Loss functions are designed for machines, they may or may not be identical to metrics.”
📌 The Data
When deciding if more data is required, it is necessary to decide how much more to gather. It is helpful to plot curves showing the relationship between training data size and model error. By extrapolating such curves, one can estimate how much additional training data would be needed to achieve a certain level of performance. Usually, adding a small fraction of the entire datatset will not have a noticeable effect on generalization error. It is therefore recommended to experiment with training dataset sizes on a logarithmic scale. If gathering more data is not feasible, the only other way to improve generalization error is to improve the learning algorithm itself. This becomes the domain of researchers and not that of applied practitioners much.
Please read this paper on the effectiveness of data in deep learning.
📌 The Model Capacity
When deciding on adjusting hyperparameters for model improvement, there are two basic approaches - manual and automatic. Manual hyperparameter tuning can work very well when there’s a good starting point. For many applications however, these starting points are not available and in those cases, automated hyperparameter tuning helps find the optimal configuration.
When there are fewer hyperparameters to tune, the common practice is to perform a grid search. There is an alternative to grid search - random search, which is lesser exhaustive and converges faster to good values of the hyperparameters. The main reason that random search finds good configuration faster than grid search is that it has no wasted experimental runs.

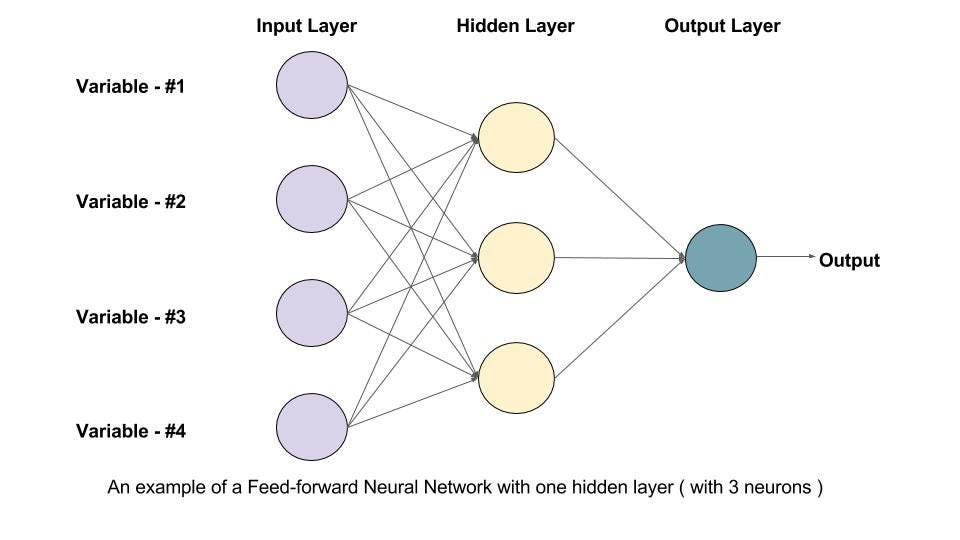
A neural network with higher number of layers and hidden units per layer has higher representational capacity that is, it’s capable of representing more complicated functions. The neural network cannot necessarily learn the complex relationships if the algorithm cannot discover while training how some functions do a better job of minimizing the cost function, or if regularization terms such as weight decay forbid some of these functions.
Hyper-parameters other than the learning rate requires monitoring of both train and test error to diagnose if the model is overfitting, then adjusting the network’s capacity appropriately.
The learning rate is perhaps the most important hyperparameter during optimization as it controls the effective model capacity in a more complicated way than others, and the capacity is highest when the learning rate is correct given the problem.

📌 The Framework
Practitioners turn typically to exisiting frameworks to solve problems with deep learning. The widely used and popular deep learning frameworks are tensorflow and pytorch. For details, please read this article.
Finally, the essential measures to track/monitor are:
Latency → delay of the model to perform a specific task
Throughput → amount of data processed in a given time
Memory → space required to store the model